こんにちはデータエンジニアの杉光です。
今年6月くらいにGAとなりデータ界隈で一瞬話題となったApplication Integrationを試した感想について書きます。
実運用で使えないか試した結果、今回は見送ることにしました。その経緯を踏まえて機能と検証内容をお伝えできればと思います。
Application Integrationとは
日本語名ではアプリケーションの統合と表記され、Google CloudのIntegration Platform as a Service(iPasS)になります。
GUIからトリガー設定や様々なアプリケーション・データソースへの接続、データ変換などのワークフローをノーコード/ローコードで作成ができます。iPasSという言葉は馴染みがなかったですが、このような機能を含むことが多いようです。
AWSでいうところのStep FunctionsとApp Flowを兼ね備えたものになるでしょうか。
全体イメージは公式のアーキテクチャ図を引用します
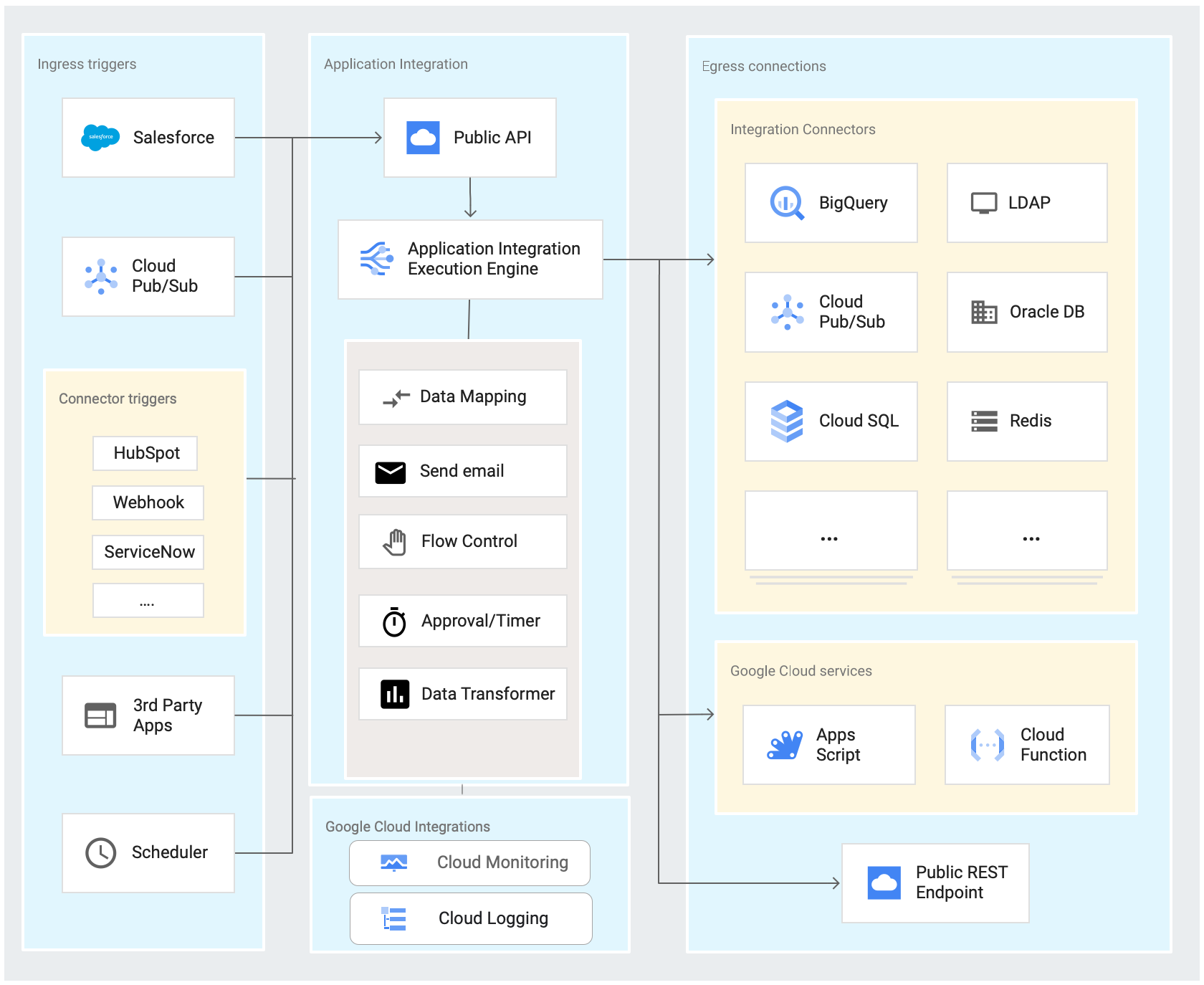
主な機能
Integrationデザイナ
フローを直感的に作成可能なビジュアルエディタ。
できることが多いので一通り機能を把握しないと何から触れば良いかわかりません。チュートリアルが複数用意されているので、近いユースケースで慣れていくのをお勧めします。
トリガー
一連のタスクを開始するイベント。 APIトリガーやScheduleトリガー、Pub/Sub、Error Catcherなどがあります。
統合タスク
タスクは入力を受け取り、処理を行い、出力を行います。大きく分けて統合タスクとGoogle Cloudサービスタスクがあり、統合タスクはApplication Integrationが提供するタスクです。
JavaScript、Send Email、Restエンドポイント呼び出し、ループ、フローの呼び出し、後述で説明するデータマッピングやコネクタどがあります。
データマッピング
ソースデータとターゲットデータのスキーママッピングを担います。
JSONの複雑なデータ構造のフィールド抽出が可能でマッピング関数を使うと簡単にマッピングできます。
連携値を任意に定義したり、それらをフロー全体の変数としてとして利用することも可能です。
コネクタ
Google CloudのサービスやThirdPatyアプリケーション、データストアに接続することができる。厳密にはIntegration Connectorsと連携します。
プレビュー含めると50種類以上あり、他の統合ツールのコネクタと引けをとらない感じがあります。
cloud.google.com
料金に注意
GCP以外のコネクタは無料枠がなく接続ノードあたり $0.70/時間 掛かります。
Google Cloudサービスのタスク
他のGoogle CloudサービスやGoogle Workspaceと連携するタスクです。 Cloud Function、DataFlow、Vertex AI、App Script、スプレッドシート、ドライブなど様々なサービスに対応しています。
試した理由
少し話題になったからというのもそうですが、当データ基盤ではBigQueryを利用しており、Zoho CRM API から取得するデータをBigQuery上で扱う必要がありました。
REST APIからデータを取得するケースは今後他にも可能性があり、その度に実装するのも手間(メンテナンスも含めて)なので、リードタイムを短くしたいと思っていました。予算的にFivetranやtoroccoなどのデータ統合ツールに手を出せなかったのもあり、GCPと連携できる安価なものを検討しました。料金については上述の通り、外部サービスと連携するときには注意が必要です。
試した内容
以下のフローでZoho CRMからBigQueryへデータを取り込むパターンを試しました。
- Zoho CRM APIを実行してデータを取得する(レスポンスはJSON形式)
- レスポンスから必要なKeyを取得する
- JSON配列をNDJSONに変換する
- GCSへファイルアップロード
- GCSのファイルをBigQueryへロード
APIトリガーを起点として、RESTエンドポイント呼び出し、GCSのコネクタ、BigQueryのコネクタをデータマッピングタスクで繋ぎ、必要な項目を選択、変換しつつ取り込む流れになります。

1. Zoho CRM APIを実行してデータを取得
今回の検証ではQuery APIを利用しました。リクエストBodyにSQLを指定し、レスポンスBodyにデータが返されます。
認証情報はAuthentication Profile画面から作成します。
Zoho CRM APIの認証仕様に基づき、OAuth 2.0 client credentialsを選び設定します。
Task inputにEndpoint、HTTP methodやRequest bodyを設定します。

今回指定したQuery APIのリクエストbodyは以下になります。
{
"select_query":"select Account_Name, Corporate_Number, Jurisdiction_Company from Accounts Where Jurisdiction_Company = 'レアジョブ' Limit 3"
}
2. レスポンスから必要なKeyを取得する
データマッピングタスクにてリクエストbodyから必要なデータ部分を取得します。
ここでは取得した値を"data"というフロー全体で使える統合変数に入れます。この時点で取得した値はJSONのArray型になっています。

3. JSON配列をNDJSONに変換する
最終的にBigQueryがロードできるフォーマット(NEWLINE DELIMITED JSON)に変換します。データマッピングタスクでは変換ができなかったので、JavaScriptタスクを使います。
以下では"data"変数から取得した値を変換し、"ndjson"変数に入れています。
/** * Function that is called during the JavaScript Task execution. * @param {IntegrationEvent} event */ function executeScript(event) { const resp = event.getParameter('data'); const ndJson = resp.map(JSON.stringify).join('\n'); event.setParameter('ndjson',ndJson); }
4. GCSへアップロード
Google Cloud Storageのコネクタタスクを使い、変換したデータをGCSバケットへアップロードします。
各コネクタでは幾つかのサービスのAPIに準じたアクションが用意されていますが、今回は UploadObject を使います。
パラメータの指定はコネクタタスク前段のデータマッピングで行います。3で設定した"ndjson"変数の値をContentへマッピングし、BucketやObectNameなどを適切な値に設定します。

5. GCSのファイルをBigQueryへロード
最後にGCSバケットへアップロードしたファイルをBigQueryに取り込みます。
BigQueryのコネクタアクションは InsertLoadJob を使います。
前手順と同様にBigQueryのコネクタタスク前段のデータマッピングからINPUTの指定を行います。GCSのURIや取り込み先のテーブルなどの他にテーブル作成や更新方法のパラメータとして以下を設定しました。
| Parameter | Value |
|---|---|
| CreateDispositon | CREATE_IF_NEEDED |
| WriteDisposition | WRITE_TRUNCATE |
| AutoDetect | true |
テスト実行と結果
操作の詳細は割愛しますが、フロー画面上部の「TEST」ボタンから実行します。 実行結果はGCS、BigQueryの内容は以下のようになりました。
GCSオブジェクトの内容
{"Account_Name":"株式会社ABC","id":"3743557000003706168","Jurisdiction_Company":"レアジョブ","Corporate_Number":null} {"Account_Name":"株式会社ABC02","id":"3743557000003706229","Jurisdiction_Company":"レアジョブ","Corporate_Number":null} {"Account_Name":"株式会社DEF","id":"3743557000003706274","Jurisdiction_Company":"レアジョブ","Corporate_Number":null}
BigQueryテーブルの内容
 スキーマの自動検出でロードしたので、JSON keyがカラム名になっていることが確認できます。
スキーマの自動検出でロードしたので、JSON keyがカラム名になっていることが確認できます。
採用しなかった理由
今回の検証で使ったAPIはJSONを返しますが、実際に使いたかったのはZip形式のバイナリを返すBulk APIでした。大量件数のデータを取得するためのものなので、非同期の取得になります。
これに対して、RESTエンドポイント呼び出しタスクのOUTPUTはString型で受けてしまうため、文字化けが発生するのでマッチしませんでした。
また、ステータスをポーリングするフローを書くのがプログラムを書くより手間と感じていたのとZipファイルを解凍する処理を書く必要があり、CloudFunctionのタスクで実装すれば可能だが、そこまでするなら全て実装しても変わらないことが主な理由です。
良い点
実運用としては使わないものの良い点はいくつかありました。
RESTエンドポイント呼び出しタスク
下記の認証プロファイルと併せてノーコードツールとして一番便利と感じた部分です。任意のAPIを叩けるのは利用ケースが大きく広がりそうですし、AWS Step Functionsも追従してか最近同じような機能をリリースしています。
Call third-party APIs - AWS Step Functions
認証プロファイル
RESTエンドポイント呼び出しタスクやコネクタ接続時の認証情報をタスクとは別に設定でき、サポートする認証タイプが充実していると感じました。
データマッピング
GUIの恩恵を一番受けられたところ。マッピング関数が便利でした。
フローをJSONエクスポートできる
コードで管理可能になる。但し認証プロファイルの設定は出力されない。 ノーコードツールで作っても設定内容はコードで管理したいし、デプロイも自動化したいとなる思います。 Google公式でintergrationcliというtoolが公開されています。 github.com 複数環境で管理されることが前提とされ、環境変数や認証プロファイルの出力も考慮されているのでCI/CDで組み入れできそうです。
終わりに
Application Integrationにてフローを作成し、APIから取得したデータをBigQueryへ取り込むイメージを少しでも持って頂けたら幸いです。 Google Driveやスプレッドシートなども連携できるので、コーポレート業務の効率化にも活用できそうです。
We're hiring!
弊社では、特に データマネジメントプラットフォーム(DMP) グループでは、
一緒に働いてくださるデータエンジニアを大募集しています。
rarejob-tech.co.jp