こんにちは。サービス開発チームの越です。
緊急事態宣言下で、在宅で仕事を行う時間が増えてきている中で、個人的に体調管理の目的でプチ断食を実践中です。
プチ断食をして、1日のうちに16時間程度ものを食べず、空腹時間をつくることで、オートファジーが働き、様々なメリットが得られるとのこと。
オートファジーとは人体の古くなった細胞を、内側から新しく生まれ変わらせる仕組みのことを言うらしいです。
さて、新しく生まれ変わらせるといえば、現在レアジョブ英会話のリプレース業務に携わっているところで、負荷試験を実施したときに使用したGatlingについての記事を書きたいと思います。
※ レアジョブ英会話のリプレース業務についての業務内容の説明はこちら
Gatlingとは
GatlingはHTTPリクエストとレスポンスを高速かつ並列に送受信して、Webアプリケーションの性能試験を行うためのツールになります。
Akkaフレームワークをベースに構築されているため、ノンブロッキングな非同期処理を軽量かつ並列に実行することが可能になっています。
Akka の特徴
Akkaのアクターは以下を提供します。
・分散性、並行性、並列性のためのシンプルで高レベルの抽象化。
・非同期でノンブロッキング、かつ、高性能のメッセージ駆動プログラミングモデル。
・とても軽量なイベント駆動処理(1 ギガバイトのヒープメモリにつき数百万のアクター)。
Akkaのアクターモデルは非常によくできており、Akkaの公式ページによると、1台のマシン上で毎秒5000万メッセージを送受信し、わずか1GBのヒープメモリの利用で250万ものアクターの生成を実現しています。
High Performance
Up to 50 million msg/sec on a single machine. Small memory footprint; ~2.5 million actors per GB of heap.
アクターは3つの要素で構成されており、1つのアクターは1つスレッドを持っています。
- 他のアクターから何らかのデータを受信するために用意するメッセージキュー
- メッセージキューから受け取ったデータを渡す先となるメッセージハンドラ
- メッセージキューからデータを取り出して、それをメッセージハンドラに渡す役目のスレッド
アクターモデルにより、Gatlingでは複数の仮想ユーザーによる、ユーザーシナリオの並列実行が実現されています。
マルチスレッドと非同期処理
非同期処理で重要になるマルチスレッドについて、ここでいうマルチスレッドとは複数のスレッドを使うということです。
OSはCPU上で実行するスレッドを適宜入れ替えます。
この時CPU上で完全に同時に実行可能なスレッドの上限はCPUコアの数と同じになるので、このあたりを踏まえてハードウェアの環境を用意する必要があります。
Gatlingの分散テスト環境を考える
負荷試験を実施しようとするときには、テストで使用するハードウェアの制限を考慮する必要があります。
過去にGatlingのgithubリポジトリのissueでも分散環境の議論がされていました。
[commented on 15 Feb 2012] Have a distributed mode for getting over the hardware and OS limits.
...
[commented on 29 Jul 2015] Done in commercial product
「ハードウェアとOSの制限を克服するための分散モードを用意します。」といって議論が始まり、「市販品の方(https://gatling.io/gatling-frontline/)で対応したよ」といってissueはcloseされている状況みたいなので、お金を払って分散テスト環境を用意するということもできます。
https://github.com/gatling/gatling/issues/415
そこで今回はAWS BatchとOSSのGatlingを使用して、分散テスト環境を構築することを考えてみます。
環境
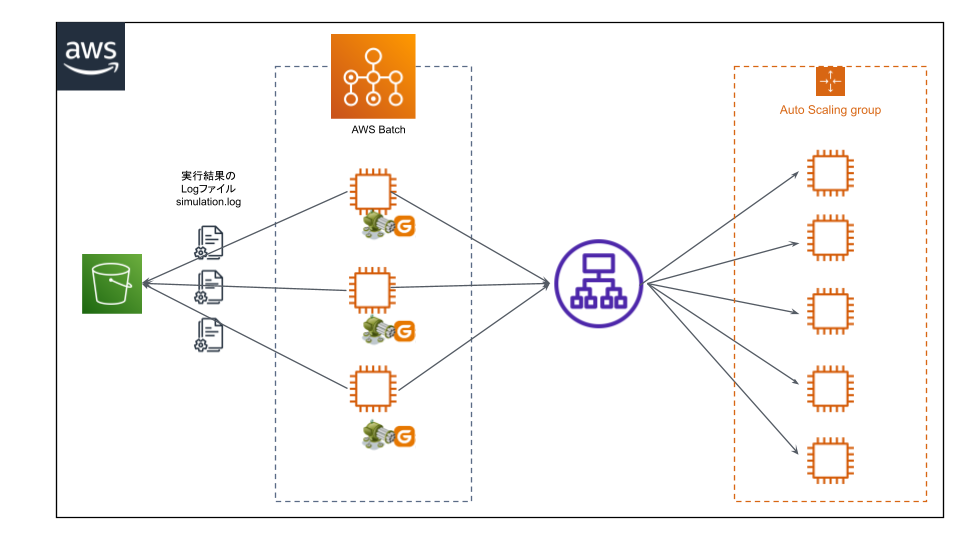
用意する環境としては以下のような構成で実施する想定で考えます。
- Gatlingによる負荷試験実施後に生成される実行結果のログファイルをアップロードするためのS3バケット
- Gatlingを動かすAWS Batch
- 攻撃対象サーバー
実行結果のログファイルがすべてS3にアップロードされたら、ログファイルをローカルにダウンロードして、レポートを生成します。
用意するファイル
Dockerfile
start.sh
gatling/
├── results/
├── conf/
└── user-files/
└── simulations/
└── gatlingTest/
├── MainSimulation.scala
└── SubSimulation.scala
Dockerfile
FROM amazonlinux AS base
WORKDIR /opt
ENV GATLING_VERSION 3.6.0
RUN mkdir -p gatling
RUN amazon-linux-extras enable corretto8 && \
yum install -y java-1.8.0-amazon-corretto \
wget \
unzip
# gatlingのインストール
RUN mkdir -p /tmp/downloads && \
wget -q -O /tmp/downloads/gatling-$GATLING_VERSION.zip \
https://repo1.maven.org/maven2/io/gatling/highcharts/gatling-charts-highcharts-bundle/$GATLING_VERSION/gatling-charts-highcharts-bundle-$GATLING_VERSION-bundle.zip && \
mkdir -p /tmp/archive && cd /tmp/archive && \
unzip /tmp/downloads/gatling-$GATLING_VERSION.zip && \
mv /tmp/archive/gatling-charts-highcharts-bundle-$GATLING_VERSION/* /opt/gatling/ && \
rm -rf /tmp/*
# AWS CLIのインストール
RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" && \
unzip awscliv2.zip && \
./aws/install && \
rm -rf awscliv2.zip aws
WORKDIR /opt/gatling
COPY start.sh .
RUN chmod 744 start.sh
ENV PATH /opt/gatling/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
ENV GATLING_HOME /opt/gatling
FROM base AS local
VOLUME ["/opt/gatling/conf", "/opt/gatling/results", "/opt/gatling/user-files"]
FROM base AS aws
COPY gatling/conf /opt/gatling/conf
COPY gatling/user-files /opt/gatling/user-files
CMD ["start.sh"]
start.sh
内容
- Gatlingの負荷試験を実施する
- 実施した結果のログファイルをS3へアップロードする
echo "AWS_BATCH_JOB_ID=$AWS_BATCH_JOB_ID";
aws --version
java -version
if [ $# != 1 ]; then
echo ERROR: Uses className as the name of the simulation to be run;
exit 1
fi
echo "gatling.sh -nr -s $1";
gatling.sh -nr -s $1
LOG_FILE_PATH=$(find /opt/gatling/results -type f -name "simulation.log" | head -n 1)
if [ -n "$LOG_FILE_PATH" ]; then
echo "aws s3 cp";
aws s3 ls s3://gatling-batch/$(date '+%Y%m%d')/
aws s3 cp $LOG_FILE_PATH s3://gatling-batch/$(date '+%Y%m%d')/"$AWS_BATCH_JOB_ID.log" --dryrun
aws s3 cp $LOG_FILE_PATH s3://gatling-batch/$(date '+%Y%m%d')/"$AWS_BATCH_JOB_ID.log"
else
echo "simulation.log daes not found"
fi
負荷試験のシュミレーションファイルの用意
今回は以下の2つのシュミレーションファイルを用意しました。
- MainSimulation.scala(0.5RPSのリクエストを60秒行うシナリオ)
- SubSimulation.scala(0.2RPSのリクエストを60秒行うシナリオ)
※ RPS:Request Per Second
ローカル環境での動作確認
Docker imageのビルド
$ > docker build --target local -t=gatling-batch-local .
Dockerコンテナの作成とシナリオの実行
$ > docker run -it --rm -v "${PWD}/gatling/conf":/opt/gatling/conf \
-v "${PWD}/gatling/user-files":/opt/gatling/user-files \
-v "${PWD}/gatling/results":/opt/gatling/results \
gatling-batch-local /bin/sh -c "gatling.sh -s computerdatabase.BasicSimulation"
AWS Batchの環境用意
AWS ECRへpushするDocker imageのビルド
$ > docker build --target aws -t=gatling-batch .
Docker imageのビルドが完了したら、ECRへpushして、AWS Batchの環境構築を行います。
ECRにpushしたimageを実行するための環境を用意します。
- ジョブ定義
- ジョブキュー
- コンピューティング環境(インスタンスロールにS3へアップロードできる権限を付与しておきます)
並列で実行したいので、ジョブキューにコンピューティング環境を複数台登録します。

AWS Batchの実行と結果
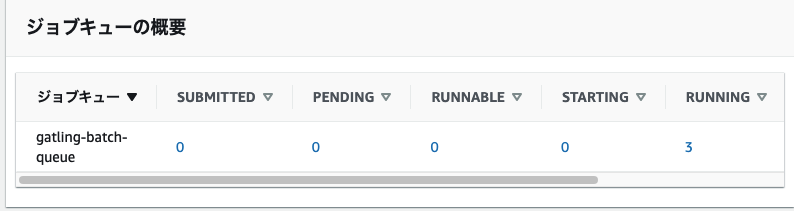
以下のようにジョブの送信を行います。
今回はMainSimulationを2つ、SubSimulationを1つ並列で実行させてみます。
$ > aws batch submit-job --job-name gatling-batch-job --job-queue gatling-batch-queue --job-definition gatling-batch:2 --container-overrides command="/bin/sh","start.sh","gatlingTest.MainSimulation"
$ > aws batch submit-job --job-name gatling-batch-job --job-queue gatling-batch-queue --job-definition gatling-batch:2 --container-overrides command="/bin/sh","start.sh","gatlingTest.MainSimulation"
$ > aws batch submit-job --job-name gatling-batch-job --job-queue gatling-batch-queue --job-definition gatling-batch:2 --container-overrides command="/bin/sh","start.sh","gatlingTest.SubSimulation"
並列に実行されてそうですね。
実行が完了すると、S3のバケットに結果のログファイルがアップロードされました。
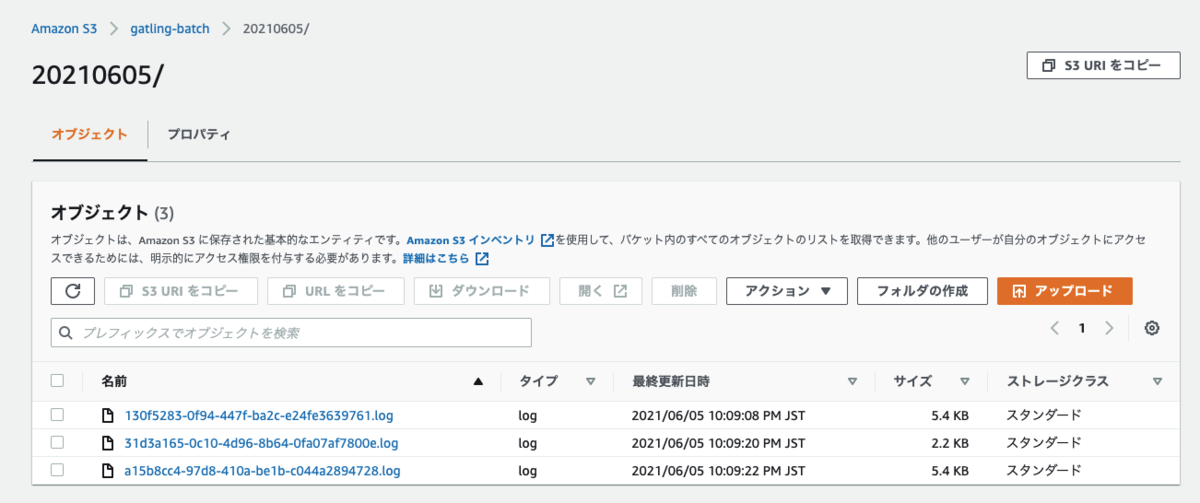
レポートの生成のために、実行結果のログをS3からローカルにダウンロードします。
$ > aws s3 cp s3://gatling-batch/$(date '+%Y%m%d')/ gatling/results/aws-batch/ --exclude "*" --include "*.log" --recursive
最後に実行結果のログからレポートを生成します。
$ > docker run -it --rm -v "${PWD}/gatling/conf":/opt/gatling/conf \
-v "${PWD}/gatling/user-files":/opt/gatling/user-files \
-v "${PWD}/gatling/results":/opt/gatling/results \
gatling-batch-local /bin/sh -c "gatling.sh -ro /opt/gatling/results/aws-batch"

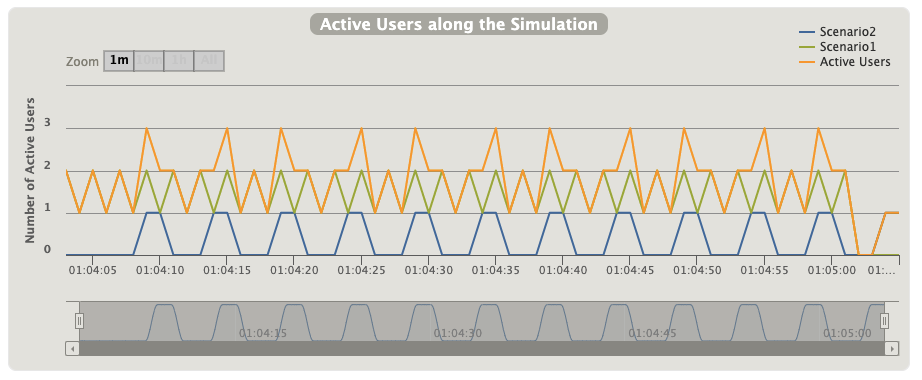
60秒間で、MainSimulationが60回(0.5RPS × 2台)、SubSimulationが12回(0.2RPS × 1台)、それぞれ意図したとおりに実行されていました。
まとめ
AWS Batchを利用することで、OSSのGatlingを使用して、分散環境を構築することができました。
攻撃用サーバーを分散して用意することで、ハードウェアの制限を気にせず、負荷試験のシナリオを用意して実行することができるようになりそうですね。






